我们帮大家精选了相关的编程文章,网友沃弘亮根据主题投稿了本篇教程内容,涉及到Python、string编码、string编码、Python编码、Python string编码相关内容,已被485网友关注,相关难点技巧可以阅读下方的电子资料。
Python string编码
一、前言
使用过Python的同学们一定被她的各种编码问题缠绕过,因为平常维护的新老项目跨越 2、3两个版本,编码问题有时更是让我苦不堪言,遂下定决心,一定要干掉他,吃透他,遂记录此篇博文以分享记录!
什么是编码?
通常我们所说的编码一般为简称, 其实在平常的应用过程,编码一般包括 编码和解码,如在编码前指定 字符集UTF-8, 那么解码时也必须为UTF-8,否则会出现所谓的 乱码
什么是字符集
字符集类似于中文,英文,是一个规则集合的抽象概念,其规定了某个文字对应的二进制数字存放方式,即为编码过程,或者二进制数字对应的文字,即为解码过程!
字符集包括如下:
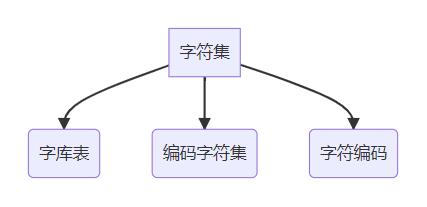
1.字库表
- 字库表是一个相当于所有可读或者可显示字符的数据库,字库表决定了整个字符集能够展现表示的所有字符的范围
2.编码字符集(通常简称 字符集)
- 编码字符集,用一个编码值code point(二进制代码)来表示一个字符(即该字符在字库表中的位置)
3.字符编码
- 字符编码,是编码字符集和实际存储数值之间的转换关系;
- 字符,是根据字符编码方案转换为一个二进制数值存储在计算机中的
一个范例
下面以一个实例解释下编解码的过程
- 字符编码: UTF-8
- 字符串:中国
- Python版本:2.7
说明:
1.编码转换方式
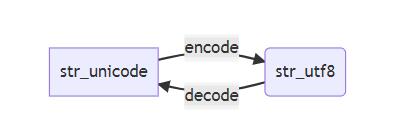
str_unicode为中间码。
即对应编码字符集 在字库表中有唯一id代表一个字符, 理论上 unicode即可以映射表示所有字符,但是为了压缩存储的位数,发展出了 utf-8、utf-16等字符编码,即在实际存储和字符展现之间又建立了一层映射,这层映射表示了 utf-8 到 unicode的方式,然后unicode又根据字库表展现改字符。
即 unicode有 utf-8及utf-16等多种方式的字符编码方案,GBK字符集 则只有一种字符编码 EUC-CN, 而对于Ascii码来说,本身即是编码字符集又是字符编码,
2.以一次Python代码执行为例, 解释 字库表、编码字符集(字符集) 与 字符编码的关系:

utf-8编码如何规定的?
单字节的字符,字节的第一位设为0,对于英语文本,UTF-8码只占用一个字节,和ASCII码完全相同;
n个字节的字符(n>1),第一个字节的前n位设为1,第n+1位设为0,后面字节的前两位都设为10,这n个字节的其余空位填充该字符unicode码,高位用0补足。
UTF-8编码方式
----------------------
0xxxxxxx
110xxxxx 10xxxxxx
1110xxxx 10xxxxxx 10xxxxxx
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
utf-8和unicode的关系
- utf 解释为诶 Unicode TransferFormat 即 转换Unicode。
- unicode是一种字符编码,规定了每个字符到数字的映射关系, 这个数字怎么存储它没有规定. 而如何存储? 几个字节表示? 这个是utf8等编码方式来规定的。
有了unicode为什么还需要utf-8呢?
- 首先 unicode 规定了所有字符的二进制编码,并没有规定如何存储
- 如果我们以统一4个字节来存储所有unicode的编码字符,那就会在表示一个字节编码的ascii部分严重浪费存储性能
- 另外因为统一4字节处理,那如果一个文件分片或者是一份缺失文件,那么此时该如何来判断我们从头读取的 4字节是一个完整的字符呢?这就会造成很大的分析复杂度,可以说 无法分析, 这也是 utf-8等编码的优点即utf-8错误编码不会向后扩散
- 综合考虑 utf-8 是一种unicode 标准的存储方案,改方案规定了如何存储unicode字符,即看上面的utf-8的规定,大白话讲就是 utf-8 可变长编码规定了 字符的起始位置,且极大可能节省存储空间,总而言之很简单就是在无序中找到秩序
二、影响Python执行的编码方案
下列四种影响Python执行的编码方案,具体实例以最后所列案例为准
1.Python解释器的默认编码
获取解释器默认编码,Python3对应的默认编码为 utf-8,Python2对应的默认编码为ascii
import sys print(sys.getdefaultencoding())
Python2设置默认编码方式,Python3解释器默认utf-8所以去除该种设置方式
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
解释器编码有什么用?
- 当调用 decode() 和 encode() 进行编码转换时候,如果未指定编码格式,会调用解释器默认编码进行编码转换
- 若未指定编码方式 而有中文出现,此时会有报错产生
2.Python源文件文件编码
python源文件的编码与解码,我们写的python程序从产生到执行的过程如下(以Pycharm为例)
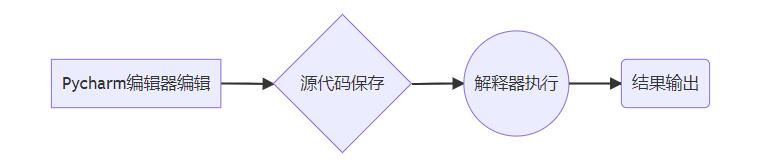
依次为
编辑器 决定源代码的编码格式(编辑器中设置)
pycharm 会根据文件开头的编码声明进行文件格式保存
此种声明保存的文件,是utf-8编码的
# coding: utf-8
此种声明保存的文件,是gbk编码的
# coding: gbk
同时也可以在setting中进行设置
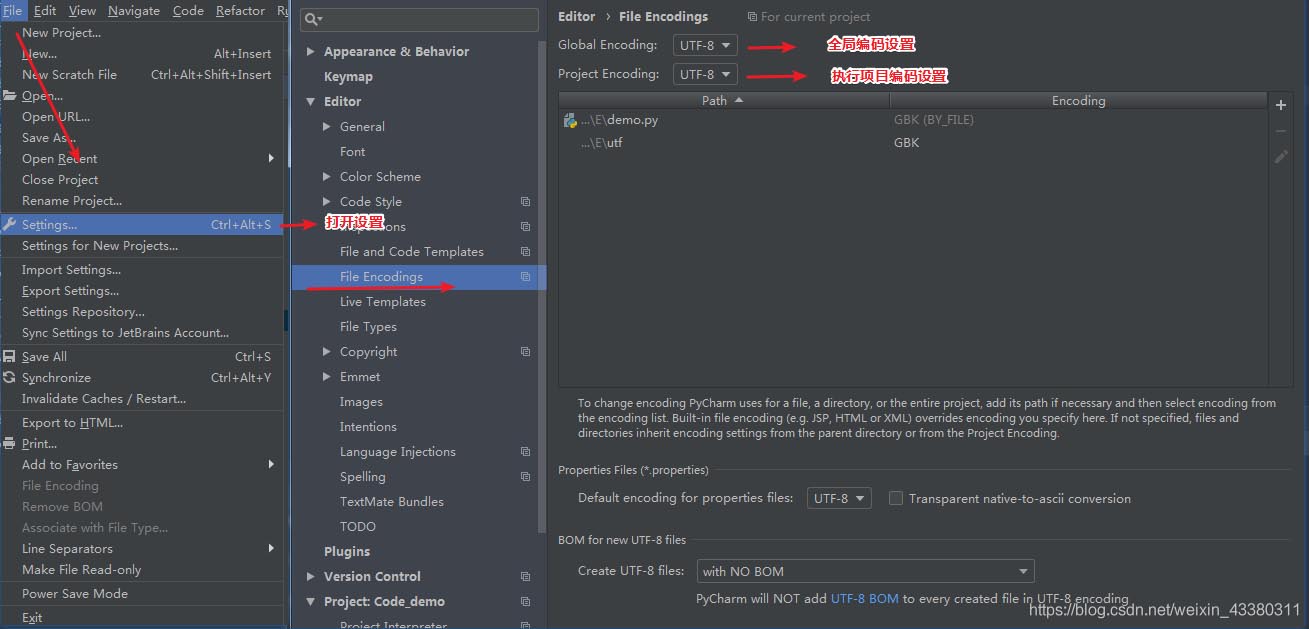
解释器按照Ascii或者声明指定的方式解码源代码, 以下是 官方文档给的解释
Python will default to ASCII as standard encoding if no other encoding hints are given.
※: Python2中会按照编码声明对源代码进行解码,如未指定 编码声明 则会以 Ascii进行解码,此时如果有中文会报错
※:Python3默认以utf-8进行解码
若未指定编码声明, 而源代码中有中文
此时Python2 会以Ascii 来进行源代码的'解码';Python3 会默认以 utf-8 进行源代码的'解码'。
若源文件编码为utf-8, 而编码声明 为gbk
这种情况会出错,因为磁盘中保存的格式时 gbk 格式的而却以 utf-8 来进行解码,则会出错。
UnicodeDecodeError: 'gbk' codec can't decode bytes in position 2-3: illegal multibyte sequence

注意1:Python3将源代码读取到内存中的字符串编码为 unicode, 这样的中间码的方式,不会出现乱码, Python2以文件头声明的方式将源代码读取到内存中
注意2:Python2 在日常编程中一定注意 文件编码 和 文件声明要一致,如 文件编码为 utf-8 则此时应该如此声明 # coding: utf-8, 若此时用gbk 做声明,则此时会乱码,一编一解 要成对
结果输出,控制台输出 或 日志文件
解释器如何知道该文件的编码格式?
# coding: utf-8
3.操作系统的语言设置
locale 模块获取 操作系统编码
import locale print locale.getdefaultencoding()
以open()函数为例
open() 函数会调用 Python操作系统默认编码进行 编解码
# coding: utf-8
import sys; reload(sys); sys.setdefaultencoding('utf-8')
str = '中国' # utf-8 bytes类型
str_unicode = str.decode() # unicode
with open('demo.txt', 'w') as f:
f.write(str) # 写入bytes类型,则此时文件编码为 utf-8
f.write(str_unicode) # 写入 unicode,则此时会根据 sys.getdefaultencoding() 来进行文件编码
linux 下 vim打开以 gbk方式写入的文件会出现乱码,因为此时会调用操作系统的编码方式进行解码
4.Terminal使用的编码
终端编码 继承自操作系统的编码
三、 Python中的编码表示范例
1.utf-8表示中文你好
print("你好".encode('utf-8'))
>>> b'\xe4\xbd\xa0\xe5\xa5\xbd'
很容易看出 其中的 16进制数 e4bda0e5a5bd
2.Python中的len表示什么
- 对于字节流(bytes: 如utf-8字节流)来说表示字节数
- 对于unicode则表示字符数
三、最后
使用范例
Pycharm编码设置
- 字符串变量级别编码
- 脚本级别的编码
- py文件级别的编码
- 显示窗口的编码
问题收集 python3 unicode字符转中文
a = "\\u4ea7\\u54c1\\u72b6\\u6001"
# 两种方式
print(eval(f'u"{a}"'))
print(a.encode().decode("unicode_escape"))
即 一个字符可以是一个中文汉字、一个英文字母、一个阿拉伯数字、一个标点符号等 ↩︎
如:Unicode、ASCII
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持码农之家。


















