为网友们分享了相关的编程文章,网友余雅诗根据主题投稿了本篇教程内容,涉及到Python、浏览器、账号共享、Python浏览器账号共享实例讲解相关内容,已被530网友关注,相关难点技巧可以阅读下方的电子资料。
Python浏览器账号共享实例讲解
Python3相关的电子书内容,介绍了关于面向对象编程、Python3方面的内容,目前豆瓣、亚马逊、当当、京东等电子书综合评分为:7.2
本篇文章介绍的内容会涉及到以下知识:
- PyQt5的使用;
- Selenium的使用;
- 代理服务器的架设和使用;
一、账号限制之痛
在如今的互联网中,免费的信息和资源占据了很大一部分,各类互联网应用提供了各行各业的资讯和资源。这是互联网能够不断繁荣和扩大的重要原因之一。
与此同时,一些收费或不公开的互联网应用则构成了互联网世界中更有价值和意义的部分。
一些限制性较低的网站,可能仅仅需要进行用户登录即可使用服务;
一些限制性中等的网站,则可能会出于账户安全或是其他方面的因素考虑,限制账号在一定时间一定IP范围内在进行登录使用;

而一些限制性很高的网站,则可能需要使用到硬件设备(比如U盾、加密狗等)+账号进行登录,部分还会配合使用到浏览器插件。
这些对账号登录的限制措施很大程度上确保了账户的安全性,但是却给使用者带来了很大的不便。
出于某些需求,我们可能需要将一个包含限制登录和使用的账号分享给多个人同时使用,这时候,我们就可以借助Python来完美实现这个需求了。
二、突破账号使用限制
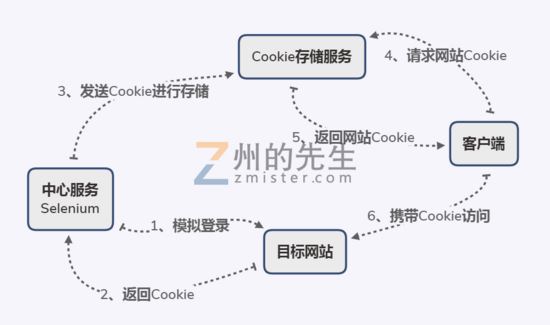
在这个方案中,我们需要使用到以下工具:
Selenium:用于模拟登录目标网站; Cookie存储服务:用于存储和返回目标网站登录成功的Cookie; 一个基于PyQt5或PiSide2的QWebEngine模块制作的浏览器;
我们首先借助Selenium对目标网站进行模拟登录并不断维持登录状态,将登录成功和更新的Cookie上传给Cookie存储服务;
然后使用PyQt5或PySide2借助其QWebEngine模块的浏览器核心自制一个浏览器。
在启动的时候从Cookie存储服务中获取最新的Cookie,将获取到的Cookie配置为浏览器默认全局Cookie。
这样,在我们打开目标网站的时候,默认就是已经登录后的状态了。如此就免除了登录限制;
三、处理账号登录IP异常
在上面提到的方案中,基本可以实现账号的共享,但是问题也是有的。比如:
多个用户同时访问的时候,同一个Cookie会匹配给多个IP地址,这对于网站后台而言,可能会将其识别为多个用户登录,从而导致频繁掉线。
多个用户访问,会使同一个账号出现多个IP地址,这对于一些安全等级较高的网站来说,会将其判定为存在疑似用户被盗号的风险,进行限制账号登录和访问。
面对这种情况,我们则需要下面这种方案:
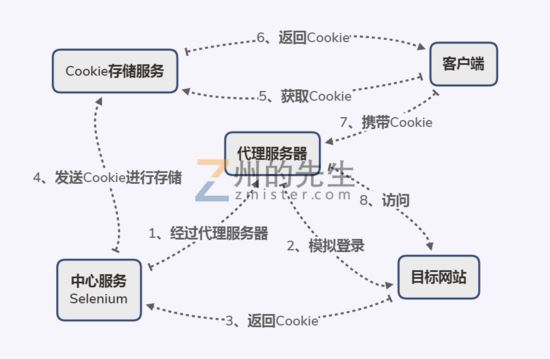
在这个方案中,我们加入了一个关键的代理服务器。
这个代理服务器会对包括Selenium和浏览器的所有请求进行转发。
Selenium通过这个代理服务器模拟登录目标网站,
自制的Qt浏览器也默认通过代理服务器访问目标网站。
在加入代理服务器之后,无论是多少个用户同时访问目标网站,所呈现出来的IP地址永远只有代理服务器的IP地址这一个。
这样,就避免了因为多个用户访问导致同一账号被多个IP地址使用,从而导致账号掉线和限制登录的风险了。
python实现随机调用一个浏览器打开网页
Python爬虫相关的电子书内容,介绍了关于Python3、网络爬虫、Python开发方面的内容,目前豆瓣、亚马逊、当当、京东等电子书综合评分为:8.9,更多相关的学习资源可以参阅 程序设计电子书、Python电子书、Python视频、等栏目。
依然使用的是 webbrowser 这个模块 来调用浏览器
关于的三种打开方式在上一篇文章中已经说过了,这里不再赘述
如果没有特意注册,那么将会是使用默认的浏览器来打开网页,如下:
#默认浏览器 #coding:utf-8 import webbrowser as web #对导入的库进行重命名 def run_to_use_default_browser_open_url(url): web.open_new_tab(url) print 'run_to_use_default_browser_open_url open url ending ....'
真正的注册一个非默认浏览器:
这里先用的firfox浏览器
#firefox浏览器
def use_firefox_open_url(url):
browser_path=r'C:\Program Files (x86)\Mozilla Firefox\firefox.exe'
#这里的‘firefox'只是一个浏览器的代号,可以命名为自己认识的名字,只要浏览器路径正确
web.register('firefox', web.Mozilla('mozilla'), web.BackgroundBrowser(browser_path))
#web.get('firefox').open(url,new=1,autoraise=True)
web.get('firefox').open_new_tab(url)
print 'use_firefox_open_url open url ending ....'
解释一下这个注册函数当前的用法
web.register() 它的三个参数
第一个为 自己给浏览器重新命的名字, 主要目的是为了在之后的调用中,使用者能够找到它
第二个参数, 可以按照这样上面的例子这样写,因为python本身将一些浏览器实例化了, 但是还是推荐 将其赋值为 None ,因为这个参数没有更好,毕竟有些浏览器python本身并没有实例化,而这个参数也不影响它的使用
第三个参数,目前所知是浏览器的路径, 不知道有没有别的写法
当然,这里只是在这里的用法, 函数本身的意思可以去源文件中查看
下面给我一些测试的实例:
#coding:utf-8
import webbrowser as web #对导入的库进行重命名
import os
import time
#默认浏览器
def run_to_use_default_browser_open_url(url):
web.open_new_tab(url)
print 'run_to_use_default_browser_open_url open url ending ....'
#firefox浏览器
def use_firefox_open_url(url):
browser_path=r'C:\Program Files (x86)\Mozilla Firefox\firefox.exe'
#这里的‘firefox'只是一个浏览器的代号,可以命名为自己认识的名字,只要浏览器路径正确
web.register('firefox', web.Mozilla('mozilla'), web.BackgroundBrowser(browser_path))
#web.get('firefox').open(url,new=1,autoraise=True)
web.get('firefox').open_new_tab(url)
print 'use_firefox_open_url open url ending ....'
#谷歌浏览器
def use_chrome_open_url(url):
browser_path=r'C:\Program Files (x86)\Google\Chrome\Application\chrome.exe'
web.register('chrome', None,web.BackgroundBrowser(browser_path))
web.get('chrome').open_new_tab(url)
print 'use_chrome_open_url open url ending ....'
#Opera浏览器
def use_opera_open_url(url):
browser_path=r'C:\Program Files (x86)\Opera\launcher.exe'
web.register('opera', None,web.BackgroundBrowser(browser_path))
web.get('chrome').open_new_tab(url)
print 'use_opera_open_url open url ending ....'
#千影浏览器
def use_qianying_open_url(url):
browser_path=r'C:\Users\Administrator\AppData\Roaming\qianying\qianying.exe'
web.register('qianying', None,web.BackgroundBrowser(browser_path))
web.get('qianying').open_new_tab(url)
print 'use_qianying_open_url open url ending ....'
#115浏览器
def use_115_open_url(url):
browser_path=r'C:\Users\Administrator\AppData\Local\115Chrome\Application\115chrome.exe'
web.register('115', None,web.BackgroundBrowser(browser_path))
web.get('115').open_new_tab(url)
print 'use_115_open_url open url ending ....'
#IE浏览器
def use_IE_open_url(url):
browser_path=r'C:\Program Files (x86)\Internet Explorer\iexplore.exe'
web.register('IE', None,web.BackgroundBrowser(browser_path))
web.get('IE').open_new_tab(url)
print 'use_IE_open_url open url ending ....'
#搜狗浏览器
def use_sougou_open_url(url):
browser_path=r'D:\Program Files(x86)\SouExplorer\SogouExplorer\SogouExplorer.exe'
web.register('sougou', None,web.BackgroundBrowser(browser_path))
web.get('sougou').open_new_tab(url)
print 'use_sougou_open_url open url ending ....'
#浏览器关闭任务
def close_broswer():
os.system('taskkill /f /IM SogouExplorer.exe')
print 'kill SogouExplorer.exe'
os.system('taskkill /f /IM firefox.exe')
print 'kill firefox.exe'
os.system('taskkill /f /IM Chrome.exe')
print 'kill Chrome.exe'
os.system('taskkill /f /IM launcher.exe')
print 'kill launcher.exe'
os.system('taskkill /f /IM qianying.exe')
print 'kill qianying.exe'
os.system('taskkill /f /IM 115chrome.exe')
print 'kill 115chrome.exe'
os.system('taskkill /f /IM iexplore.exe')
print 'kill iexplore.exe'
#测试运行主程序
def broswer_test():
url='https://www.baidu.com'
run_to_use_default_browser_open_url(url)
use_firefox_open_url(url)
#use_chrome_open_url(url)
use_qianying_open_url(url)
use_115_open_url(url)
use_IE_open_url(url)
use_sougou_open_url(url)
time.sleep(20)#给浏览器打开网页一些反应时间
close_broswer()
if __name__ == '__main__':
print '''''
*****************************************
** Welcome to python of browser **
** Created on 2017-05-07 **
** @author: Jimy _Fengqi **
*****************************************
'''
broswer_test()
好了,上面的程序是测试实例, 下面对这些内容做一个整合,简化一下代码,来实现本文的根本目的
#coding:utf-8
import time
import webbrowser as web
import os
import random
#随机选择一个浏览器打开网页
def open_url_use_random_browser():
#定义要访问的地址
url='https://www.baidu.com'
#定义浏览器路径
browser_paths=[r'C:\Program Files (x86)\Mozilla Firefox\firefox.exe',
r'C:\Program Files (x86)\Google\Chrome\Application\chrome.exe',
r'C:\Program Files (x86)\Opera\launcher.exe',
r'C:\Users\Administrator\AppData\Roaming\qianying\qianying.exe',
r'C:\Users\Administrator\AppData\Local\115Chrome\Application\115chrome.exe',
r'C:\Program Files (x86)\Internet Explorer\iexplore.exe',
r'D:\Program Files(x86)\SouExplorer\SogouExplorer\SogouExplorer.exe'
]
#选择一个浏览器
def chose_a_browser_open_url(browser_path,url):
#如果传入的浏览器位置不存在,使用默认的浏览器打开
if not browser_path:
print 'using default browser to open url'
web.open_new_tab(url)#使用默认浏览器,就不再结束进程
else:
#判断浏览器路径是否存在
if not os.path.exists(browser_path):
print 'current browser path not exists,using default browser'
#浏览器位置不存在就使用默认的浏览器打开
browser_path=''
chose_a_browser_open_url(chose_a_browser_open_url,url)
else:
browser_task_name=browser_path.split('\\')[-1]#结束任务的名字
browser_name=browser_task_name.split('.')[0]#自定义的浏览器代号
print browser_name
web.register(browser_name, None,web.BackgroundBrowser(browser_path))
web.get(browser_name).open_new_tab(url)#使用新注册的浏览器打开网页
print 'using %s browser open url successful' % browser_name
time.sleep(5)#等待打开浏览器
kill_cmd='taskkill /f /IM '+browser_task_name#拼接结束浏览器进程的命令
os.system(kill_cmd) #终结浏览器
browser_path=random.choice(browser_paths)#随机从浏览器中选择一个路径
chose_a_browser_open_url(browser_path,url)
if __name__ == '__main__':
print '''''
*****************************************
** Welcome to python of browser **
** Created on 2017-05-07 **
** @author: Jimy _Fengqi **
*****************************************
'''
open_url_use_random_browser()
PS:本程序在windows上面运行,python版本是2.7



















建立一个http会话 首先,我们需要建立一个http请求的会话session,使我们请求验证码的请求和提交登陆信息的请求处于同一个session中,否则即使获得了验证码也无法通过验证。 这里我们直接将初始cookie信息传递给会话session,在http会话的过程中,该session会自动的通过HTTP header更新cookie信息,所以之后就不需要我们手动更新cookie了。 s = requests.Session() s.headers = header s.cookies = cookie