为网友们分享了相关的编程文章,网友通宏峻根据主题投稿了本篇教程内容,涉及到c++的cpp文件、c++消除注释、cpp、注释、C++去除cpp文件注释相关内容,已被143网友关注,下面的电子资料对本篇知识点有更加详尽的解释。
C++去除cpp文件注释
问题:读取一个cpp文件,去除其中所有的单行注释(//)和多行注释(/**/),将去除注释后的内容写入一个新文件。
注意:
不能去除字符串中的任何字符,如 "asdf//gh/**/k" 需要原样输出
能够识别转义的双引号(\")和非转义的双引号("),如:
- '\"'(单引号中的转义双引号字符)
- "asdf\"" (字符串中的转义双引号不能表示字符串结束)
- \"aaa"bcdef" (同理,转义双引号不能表示字符串开始)
命令行参数为:
- 参数1:原文件名
- 参数2:新文件名
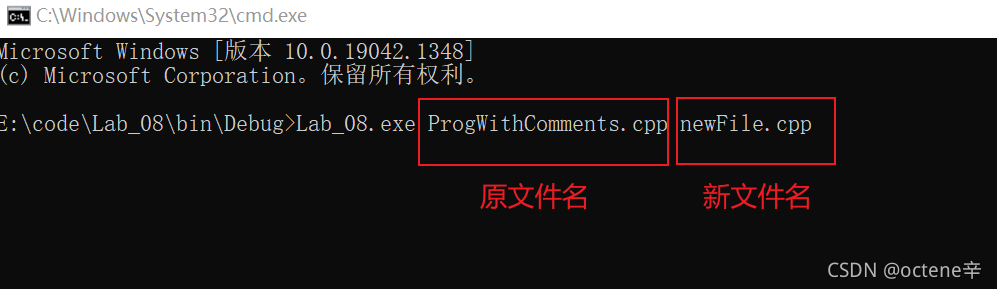
一、文件流
引入
#include#include using namespace std; bool stripComment(string infile,string outfile){ ifstream ifs; ifs.open(infile,ios::in); if(!ifs.is_open()){ cout<<"fail to read!"<
二、具体逻辑
1.如何循环读入字符
这是最关键的一步。我们利用ifstream对象的get()方法无条件地读取文件流中的一个字符。什么叫无条件?这是与>>运算符相区分的,>>会自动跳过所有空白字符,也就是说,它读不到空格、\t、\n,这不符合我们的需求。
同时,ifstream对象有一个putback()方法,它就是将一个字符重新放回文件流的末尾,下一次get(),我们还会读到它:这有时候很有用。
get(char c) 会把文件流的末尾一个字符取出,放到char型变量c中。这个函数的返回值可以被转换成一个布尔值,表示流的状态:如果流状态正常,则返回true;如果流状态不正常(bad,fail,读到文件尾符号),返回false。
char temp1{};
while(ifs.get(temp1)){
ofs<最简单的情况是,利用get()循环读入字符并存入temp1变量中,再把temp1写入新文件中。最终我们会得到与原文件一样的副本。
2.处理单行和多行注释
这两种东西有同一个特点:都是以 / 开头的。所以我们读取到 / 这个字符时,就要小心一点:它是不是意味着我读到了一个注释?
我们可以在此基础上再读一个字符,存入另一个字符变量temp2中,看看它是什么情况:
- / :一定读到了一个单行注释
- * :一定读到了一个多行注释
- 其他字符:刚刚读到的 / 只是一个普通的正斜杠
对于第三种情况, 我们这样善后:
- 立刻输出temp1(/)
- 把temp2放回文件流中等待下一次读取,因为它可能有用(比如,是个双引号)
- 跳转到一开始的while循环
对于第一种情况:
- 一直向后读字符,直到读到一个换行符\n
- 将这个换行符放回文件流
- 跳转到一开始的while循环
第二种情况最麻烦,我们必须找一个办法确定什么时候多行注释才能结束。C++的语法规定, /* 与最近的 */ 之间是多行注释,那么我们只需找最近的 */ 即可。
- while循环一直向后读字符,直到找到一个 *
- 再读一个字符,放入字符变量temp3中。
- temp3是一个 / ,恭喜!我们已经找到多行注释的完整范围,只要简单地break掉当前的while循环,再跳转到开始的while循环就可以。不用输出任何东西。
- 不好,temp3不是 / ,这意味着我们没有找到多行注释的终止处。此时应该将temp3放回文件流,返回步骤1:这是很必要的,如果temp3正好是一个* ,它之后恰好是一个 / 呢?我们不能丢弃任何“可能有用”的字符!
while(ifs.get(temp1)){
//处理 "//" 或 "/**/"
if(temp1=='/'){
checkStatus=true;
ifs.get(temp2);//再读一个字符
if(temp2=='/'){//处理"//"
checkStatus=false;
while(ifs.get(temp2)){//一直向后读字符,直到读到一个换行符\n
if(temp2=='\n') break;
}
ifs.putback('\n');//将换行符放回文件流
continue;//跳转到一开始的while循环
}else if(temp2=='*'){//处理 "/**/"
checkStatus=true;
while(ifs.get(temp3)){
if(temp3=='*'){//找到一个*
ifs.get(temp4);
if(temp4=='/'){//找到一个/ checkStatus=false; break;
}else{//没找到/ ifs.putback(temp4); continue;
}
}
}
continue;
}else{//只读到了一个 /
checkStatus=false;
ifs.putback(temp2);//把temp2放回文件流中等待下一次读取
}
}
ofs<3.注意字符串
我们在2中的操作会破坏字符串中的一些内容,比如:
处理前:"asdf//gh/**/k"
处理后(//被当成了单行注释):"asdf
我们的需求是保留字符串原封不动输出。
因此,当temp1没有读到 / 时(即没有进入处理注释的逻辑),temp1读到了一个 " ,我们就要小心了:后面的内容是字符串,原样输出即可。
- 立刻输出temp1。
- 循环读入后面的字符,存入temp2中,立即输出temp2。
- 检查刚刚输出的temp2是不是 " ,如果是,结束当前循环并跳转到一开始的while循环
while(ifs.get(temp1)){
//处理 "//" 或 "/**/"
//省略...
//处理字符串
if(temp1=='\"'){
ofs<4.注意转义双引号
以上的两块逻辑能解决一般问题,但在以下的例子中会出错:
char c='\"';
const char* p1 = "sdjksd\"\\d//fj/*kdhjk\"dsfjl*/dks";
int main()
{
cout << "//The number of queens (4 -- 12) :// " ;
}最后的结果是:
char c='\"';
const char* p1 = "sdjksd\"\\d//fj/*kdhjk\"dsfjl*/dks";
int main()
{
cout << "
}为什么呢?其实是转义双引号(\")在作怪,因为我们目前的逻辑将转义双引号与表示字符串开头与结尾的普通双引号混为一谈,导致字符串的边界出现混乱。
以下红色部分表示程序所认为的字符串,蓝色部分表示程序认为是注释的地方():

可以看出这个问题挺严重的,首要之急就是区分转义双引号和普通双引号。
C++的文件流是逐个字符读取的,也就是说,\" 在get()时,第一次会得到 \ ,第二次会得到 " 。
另一个有用的信息就是,C++的字符串边界永远是普通双引号,而不是转义双引号。
1>防止转义双引号作为字符串开头
- 当没有进入处理注释的逻辑时,读到了一个 \
- 立刻输出 \ 本身
- 读取下一个字符存入temp2中
- 立刻输出temp2
- 跳转到一开始的while循环
为什么这样做呢?分析一下,因为 \ 与它后面的字符已经被转义(它们是一个整体),\ 后面的字符不能被认为是代码语法的一部分。比如:\ 之后的 " 不能被认为是普通的双引号,\ 之后的 / 也不能被认为是一个代表注释开头的 /。反斜杠后面的字符从语法上来说应该直接输出。
注:处理注释时不需这种逻辑,注释里的 \ 没有什么特殊的意义,和普通字符地位一样。它不能影响后面那个字符的含义。
/*aaaaa\*/
仍然表示一个多行注释
2>防止转义双引号作为字符串结尾
要在字符串的输出逻辑中增加检查机制。
- 刚刚输出的字符(temp2)如果是一个 \
- 读取下一个字符并直接输出
- 继续执行当前的while输出循环,直到temp2是一个双引号为止
while(ifs.get(temp1)){
//处理 "//" 或 "/**/"
//...省略
//防止\"作为字符串开头
if(temp1=='\\'){
checkStatus=true;
ofs<5.增加简单的查错功能
当我们发现了 /* 或 " 时,这意味着我们开始进行注释边界的确定或字符串边界的确定。当发现了一个 \ 之后,\ 后面理应有一个字符。
如果我们:
- 找到了 " 却始终未找到对应的 "
- 找到了 /* 却始终没有找到 */
- 找到了 \ 后面却无字符
这三种情况意味着原文件的语法一定有问题,我们用一个变量checkStatus表示。当开始进行"寻找"过程,checkStatus被设为true。当寻找结束后,变量的值被设为false。如果文件流结束,此变量依然为true,那么应提醒用户,文件的语法有问题。
完整代码如下:
#include#include using namespace std; bool stripComment(string infile,string outfile){ ifstream ifs; ifs.open(infile,ios::in); if(!ifs.is_open()){ cout<<"fail to read!"<
三、正则实现(Java)
这是题外话,但其实正则表达式也能实现这一功能。
由于C++的正则似乎不支持后发断言,所以使用了Java的正则类。
主要思路:
- 读取待去除注释的文本,存入一个字符串中。
- 创建两个正则表达式,一个匹配注释和字符串,另一个只能匹配注释。
- 对该字符串循环匹配第一个正则表达式,得到结果str。
- 若str符合第二个正则表达式,则记下str在原字符串中的起始下标和结束下标,将二者都存入ArrayList对象中。
- 匹配结束后,遍历原字符串,如果字符下标位于”存储下来的注释区域的起始和结束下标“之间,就不输出这些字符。
package project1100;
import java.util.ArrayList;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class mainTest {
public static void main(String[] args) {
String str2=
"const char *qq=\"/**/\";\n" +
"const char *pp=/**\"\\\"007*/\"/**/\";\n" +
"const char *rr=/**'\\'007*/\"/**/\"\"//\";";
//匹配注释和字符串
Pattern pattern1=Pattern.compile("(/((/.*)|(\\*[\\S\\s]*?\\*/)))|((? arrayList=new ArrayList();
Matcher matcher1=pattern1.matcher(str2);
//匹配注释和字符串
while(matcher1.find()){
//是注释,下标存入容器中
if(pattern2.matcher(matcher1.group(0)).matches()) {
arrayList.add(matcher1.start(0));
arrayList.add(matcher1.end(0));
}
}
//选择输出
label:for(int i=0;i=arrayList.get(j*2)&&i 图解:
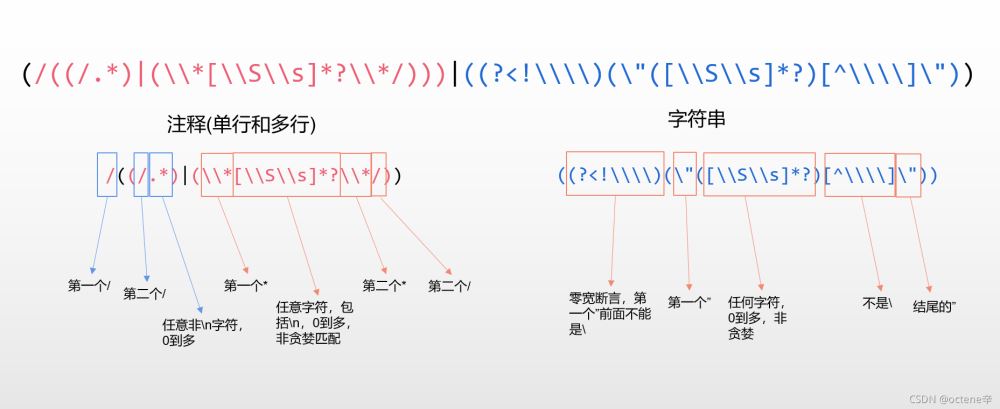
可能仍有疏漏,请各位大佬指正。
结语:
去除代码中的注释,看似简单,实则要考虑诸多情况。这是一个极其考验思维细致度的问题,希望大家都能考虑到每一种情况,找到自己最好理解的思路。
到此这篇关于C++如何去除cpp文件注释的文章就介绍到这了,更多相关C++去除cpp文件注释内容请搜索码农之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持码农之家!








