本站精选了一篇相关的编程文章,网友司和泰根据主题投稿了本篇教程内容,涉及到Python稀疏矩阵、Python scipy.sparse包、Python稀疏矩阵相关内容,已被388网友关注,如果对知识点想更进一步了解可以在下方电子资料中获取。
Python稀疏矩阵
1. 前言
数组和矩阵是数值计算的基础元素。目前为止,我们都是使用NumPy的ndarray数据结构来表示数组,这是一种同构的容器,用于存储数组的所有元素。
有一种特殊情况,矩阵的大部分元素都为零,这种矩阵被称为稀疏矩阵。对于稀疏矩阵,将所有零保存在计算机内存中的效率很低,更合适的方法是只保存非零元素以及位置信息。于是SciPy应运而生,为稀疏矩阵的表示及其线性代数运算提供了丰富易用的接口。
2. 导入包
SciPy中提供了稀疏矩阵模块scipy.sparse,为稀疏矩阵的表示及其线性代数运算提供了丰富易用的接口。
import scipy.sparse as sp import scipy.sparse.linalg import scipy.linalg as la
3. 稀疏矩阵总览
There are seven available sparse matrix types:
1. csc_matrix: Compressed Sparse Column format
2. csr_matrix: Compressed Sparse Row format
3. bsr_matrix: Block Sparse Row format
4. lil_matrix: List of Lists format
5. dok_matrix: Dictionary of Keys format
6. coo_matrix: COOrdinate format (aka IJV, triplet format)
7. dia_matrix: DIAgonal format
- sp.coo_matrix(坐标的列表)描述:将非零值及其行列信息保存在一个列表。构造简单,添加元素方便,但访问元素效率低下;
- sp.lil_matrix(列表的列表):将每行的非零元素列索引保存在一个列表,将对应值保存在另一个列表。支持切片操作,但不方便进行数学运算;
- sp.dok_matrix(值的字典):将非零值保存在字典,非零值的坐标元组作为字典的键。构造简单,可快速添加删除元素,但不方便进行数学运算;
- sp.dia_matrix(对角矩阵):矩阵的对角线列表 。对于对角矩阵非常有效 ,但不适用非对角矩阵;
- sp.csc_matrix 和 sp.csr_matrix(压缩列格式和压缩行格式):将值与行列索引的数组一起存储。对于矩阵的向量乘法很高效,但构造相对复杂;
- sp.bsr_matrix(块稀疏矩阵):与CSR类似,用于具有稠密子矩阵的稀疏矩阵。对于此类特殊矩阵很高效,但不适用一般矩阵。
注意:
- 为了有效地构建矩阵,使用dok_matrix或者lil_matrix,lil_matrix类支持基本的切片和索引操作,语法与NumPy的arrays相似。
- COO格式也能有效率地构建矩阵。尽管与NumPy有许多相似性,但是强烈不建议使用NumPy的函数直接对稀疏矩阵格式进行操作,因为可能导致不正确的结果。如果将NumPy的函数用在这些矩阵上,首先检查SciPy在对应的稀疏矩阵类上有没有已经实现的操作,或者使用toarray()方法将稀疏矩阵对象转为NumPy的array。
- 实现乘法与转置操作,则转为CSC或CSR格式,lil_matrix格式是基于行的,所以转为为CSR比CSC更有效率。所有的转换在CSR,CSC和COO格式之间都是有效的,线性时间操作。
4. 稀疏矩阵详细介绍
4.1 coo_matrix
coo_matrix是最简单的存储方式。采用三个数组row、col和data保存非零元素的行下标,列下标与值。这三个数组的长度相同一般来说,coo_matrix主要用来创建矩阵,因为coo_matrix无法对矩阵的元素进行增删改等操作,一旦创建之后,除了将之转换成其它格式的矩阵,几乎无法对其做任何操作和矩阵运算。

为了创建sp.coo_matrix对象,需要创建非零值、行索引以及列索引的列表或数组,并将其传递给生成函数sp.coo_matrix。
values = [1, 2, 3, 4] rows = [0, 1, 2, 3] cols = [1, 3, 2, 0] A = sp.coo_matrix((values, (rows, cols)), shape=[4, 4]) A

>>> A.toarray()
array([[1, 0, 0, 0],
[0, 0, 0, 2],
[0, 0, 3, 0],
[4, 0, 0, 0]])
>>> type(A)
>>> type(A.toarray())
SciPy的sparse模块中稀疏矩阵的属性大部分派生自NumPy的ndarray对象,同时也包括nnz(非零元素数目)和data(非零值)等属性。
A.shape, A.size, A.dtype, A.ndim
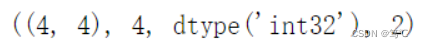
A.nnz, A.data

对于sp.coo_matrix对象,还可以使用row和col属性来访问底层的行列坐标数组。
A.row, A.col
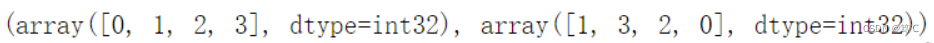
4.2 dok_matrix
dok_matrix适用的场景是逐渐添加矩阵的元素。dok_matrix的策略是采用字典来记录矩阵中不为0的元素。所以字典的key存的是记录元素的位置信息的元祖,value是记录元素的具体值。
>>> S = sparse.dok_matrix((5, 5), dtype=np.float32)
>>> for i in range(5):
for j in range(5):
S[i,j] = i+j # 更新元素
>>> S.toarray()
[[0. 1. 2. 3. 4.]
[1. 2. 3. 4. 5.]
[2. 3. 4. 5. 6.]
[3. 4. 5. 6. 7.]
[4. 5. 6. 7. 8.]]
优点:对于递增的构建稀疏矩阵很高效,比如定义该矩阵后,想进行每行每列更新值,可用该矩阵。当访问某个单元,只需要O(1)
缺点:不允许重复索引(coo中适用),但可以很高效的转换成coo后进行重复索引。
4.3 lil_matrix
lil_matrix适用的场景也是逐渐添加矩阵的元素。与dok不同,lil_matrix则是使用两个列表存储非0元素。data保存每行中的非零元素,rows保存非零元素所在的列。这种格式也很适合逐个添加元素,并且能快速获取行相关的数据。
>>> l = sparse.lil_matrix((4, 4))
>>> l[1, 1] = 1
>>> l[1, 3] =2
>>> l[2, 3] = 3
>>> l.toarray()
array([[0., 0., 0., 0.],
[0., 1., 0., 2.],
[0., 0., 0., 3.],
[0., 0., 0., 0.]])
>>> l.data
array([list([]), list([1.0, 2.0]), list([3.0]), list([])], dtype=object)
>>> l.rows
array([list([]), list([1, 3]), list([3]), list([])], dtype=object)
优点:适合递增的构建成矩阵、转换成其它存储方式很高效、支持灵活的切片。
缺点:当矩阵很大时,考虑用coo、算术操作,列切片,矩阵向量内积操作慢。
4.4 dia_matrix
如果稀疏矩阵仅包含非0元素的对角线,则对角存储格式(DIA)可以减少非0元素定位的信息量。这种存储格式对有限元素或者有限差分离散化的矩阵尤其有效。dia_matrix通过两个数组确定: data和offsets。其中data对角线元素的值;offsets:第i个offsets是当前第i个对角线和主对角线的距离。data[k:]存储了offsets[k]对应的对角线的全部元素。例子如下:

>>> data = np.array([[1, 2, 3, 4], [5, 6, 0, 0], [0, 7, 8, 9]])
>>> offsets = np.array([0, -2, 1])
>>> sparse.dia_matrix((data, offsets), shape=(4, 4)).toarray()
array([[1, 7, 0, 0],
[0, 2, 8, 0],
[5, 0, 3, 9],
[0, 6, 0, 4]])
注意:offsets[0]=0表示第0个对角线与主对角线的距离为0,表示第0个对角线就是主对角线,data[0]就是第0个对角线的值。offsets[1]=-2表示第1个对角线与主对角线距离为-2,此时该对角线在主对角线的左下方,对角线上数值的数量为4-2=2,对应的值为data[1, :2+1],此时data[1, 3:]为无效的值,在构造对角稀疏矩阵时不起作用。offsets[2]=1表示第2个对角线与主对角线距离为1,此时该对角线在主对角线的右上方,对角线上数值的数量为4-1=3,对应的值为data[2, 1:],此时data[2, :1]为无效的值,在构造对角稀疏矩阵时不起作用。
4.5 csc_matrix & csr_matrix
csr_matrix是按行对矩阵进行压缩的,csc_matrix则是按列对矩阵进行压缩的。通过row_offsets,column_indices,data来确定矩阵。column_indices,data与coo格式的列索引与数值的含义完全相同,row_offsets表示元素的行偏移量。例子如下,
>>> indptr = np.array([0, 2, 3, 6])
>>> indices = np.array([0, 2, 2, 0, 1, 2])
>>> data = np.array([1, 2, 3, 4, 5, 6])
>>> csr_matrix((data, indices, indptr), shape=(3, 3)).toarray()
array([[1, 0, 2],
[0, 0, 3],
[4, 5, 6]])
注意:indices和data分别表示列索引和数据,第 i 行的列索引存储在indices[indptr[i]:indptr[i+1]] 中,对应的值为data[indptr[i]:indptr[i+1]]。即第0行的列索引为indices[0:2]=[0,2],值为data[0:2]=[1,2];第1行的列索引为indices[2:3]=[2],值为data[2:3]=[3]…
CSR格式常用于读入数据后进行稀疏矩阵计算。
两者的优缺点互反:
- CSR优点:高效的稀疏矩阵算术操作、高效的行切片、快速地矩阵向量内积操作;
- CSR缺点:缓慢地列切片操作(可以考虑csc)、转换到稀疏结构代价较高(可以考虑lil,dok)。
- CSC优点:高效的稀疏矩阵算术操作、高效的列切片、快速地矩阵向量内积操作(不如csr,bsr块);
- CSC缺点:缓慢地行切片操作(可以考虑csr)、 转换到稀疏结构代价较高(可以考虑lil,dok)。
4.6 bsr_matrix
基于行的块压缩,通过row_offsets,column_indices,data来确定矩阵。与csr相比,只是data中的元数据由0维的数变为了一个矩阵(块),其余完全相同。
>>> indptr = np.array([0,2,3,6])
>>> indices = np.array([0,2,2,0,1,2])
>>> data = np.array([1,2,3,4,5,6]).repeat(4).reshape(6,2,2)
>>> bsr_matrix((data,indices,indptr), shape=(6,6)).todense()
matrix([[1, 1, 0, 0, 2, 2],
[1, 1, 0, 0, 2, 2],
[0, 0, 0, 0, 3, 3],
[0, 0, 0, 0, 3, 3],
[4, 4, 5, 5, 6, 6],
[4, 4, 5, 5, 6, 6]])
优点:很类似于csr,更适合于矩阵的某些子矩阵很多值,在某些情况下比csr和csc计算更高效。
5. 稀疏矩阵的存取
5.1 用save_npz保存单个稀疏矩阵
>>> scipy.sparse.save_npz('sparse_matrix.npz', sparse_matrix)
>>> sparse_matrix = scipy.sparse.load_npz('sparse_matrix.npz')
稀疏矩阵存储大小比较:
a = np.arange(100000).reshape(1000,100)
a[10: 300] = 0
b = sparse.csr_matrix(a)
# 稀疏矩阵压缩存储到npz文件
sparse.save_npz('b_compressed.npz', b, True) # 文件大小:100KB
# 稀疏矩阵不压缩存储到npz文件
sparse.save_npz('b_uncompressed.npz', b, False) # 文件大小:560KB
# 存储到普通的npy文件
np.save('a.npy', a) # 文件大小:391KB
# 存储到压缩的npz文件
np.savez_compressed('a_compressed.npz', a=a) # 文件大小:97KB
对于存储到npz文件中的CSR格式的稀疏矩阵,内容为:
data.npy format.npy indices.npy indptr.npy shape.npy
6. 总结
加载数据文件时使用coo_matrix快速构建稀疏矩阵,然后调用to_csr()、to_csc()、to_dense()把它转换成CSR或稠密矩阵(numpy.matrix)。
coo_matrix格式常用于从文件中进行稀疏矩阵的读写,而csr_matrix格式常用于读入数据后进行稀疏矩阵计算。
7. 参考
【1】https://blog.csdn.net/winycg/article/details/80967112
【2】https://blog.csdn.net/vor234/article/details/124935384
到此这篇关于Python稀疏矩阵scipy.sparse包使用详解的文章就介绍到这了,更多相关Python稀疏矩阵内容请搜索码农之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持码农之家!









