我们帮大家精选了相关的编程文章,网友宦沛岚根据主题投稿了本篇教程内容,涉及到Python随机梯度下降法、Python梯度下降法、Python梯度下降、Python随机梯度下降法相关内容,已被376网友关注,如果对知识点想更进一步了解可以在下方电子资料中获取。
Python随机梯度下降法
随机梯度下降法
为什么使用随机梯度下降法?
如果当我们数据量和样本量非常大时,每一项都要参与到梯度下降,那么它的计算量时非常大的,所以我们可以采用随机梯度下降法。
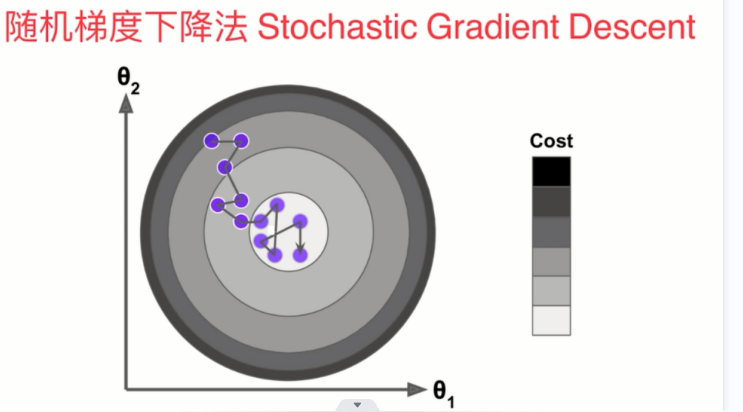
随机梯度下降法中的学习率必须是随着循环的次数增加而递减的。如果eta取一样的话有可能在非常接近我们的最优值时会跳过,所以随着迭代次数的增加,学习率eta要随之减小,我们可以用模拟退火的思想实现(如下图所示),t0和t1是一个常数,定值,其通常是根据经验取得一些值。

随机梯度下降法的实现
随机梯度下降法的公式如下图所示,其中挑出一个样本出来计算。

先创建x,y,以下取10000个样本
import numpy as np m = 10000 x = np.random.random(size=m) y = x*3 + 4 + np.random.normal(size=m)
写入函数
def dj_sgd(theta, x_i, y_i): # 传入一个样本,获取对应的梯度
return x_i.T.dot(x_i.dot(theta)-y_i)*2 # MSE
def sgd(X_b, y, initial_theta, n_iters): # 求出整个theta的函数
def learning_rate(i_iter):
t0 = 5
t1 = 50
return t0/(i_iter+t1)
theta = initial_theta
i_iter = 1
while i_iter <= n_iters:
index = np.random.randint(0, len(X_b))
x_i = X_b[index]
y_i = y[index]
gradient = dj_sgd(theta, x_i, y_i) # 求导数
theta = theta - gradient*learning_rate(i_iter) # 求步长
i_iter += 1
return theta
调用函数,求出截距和系数
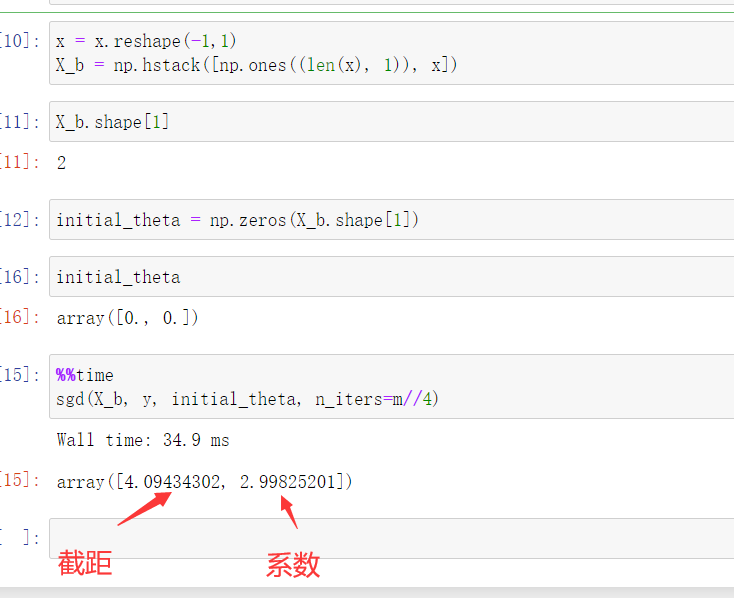
以上随机梯度的缺点是不能照顾到每一点,因此需要进行改进。
以下对其中的函数进行修改。
def dj_sgd(theta, x_i, y_i): # 传入一个样本,获取对应的梯度
return x_i.T.dot(x_i.dot(theta)-y_i)*2 # MSE
def sgd(X_b, y, initial_theta, n_iters): # 求出整个theta的函数
def learning_rate(i_iter):
t0 = 5
t1 = 50
return t0/(i_iter+t1)
theta = initial_theta
m = len(X_b)
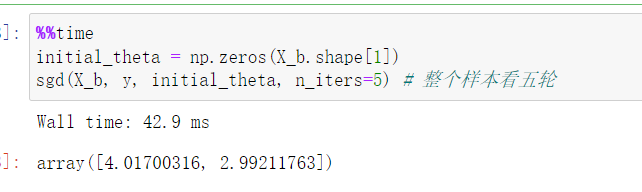
for cur_iter in range(n_iters): # 每一次循环都把样本打乱,n_iters的代表整个样本看几轮
random_indexs = np.random.permutation(m)
X_random = X_b[random_indexs]
y_random = y[random_indexs]
for i in range(m):
theta = theta - learning_rate(cur_iter*m+i) * (dj_sgd(theta, X_random[i], y_random[i]))
return theta
与前边运算结果进行对比,其耗时更长。
到此这篇关于Python机器学习之随机梯度下降法的实现的文章就介绍到这了,更多相关Python随机梯度下降法内容请搜索码农之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持码农之家!








