给大家整理了相关的编程文章,网友车语蓉根据主题投稿了本篇教程内容,涉及到MyBatis discriminator标签、MyBatis discriminator、MyBatis discriminator标签相关内容,已被266网友关注,相关难点技巧可以阅读下方的电子资料。
MyBatis discriminator标签
一、什么业务情况会使用discriminator标签?
假设我们有一张user表:

使用查询语句select * from user有如下需求
当用户年龄为18岁时查询结果显示生日信息。
当用户年龄不为18岁时查询结果不显示生日信息。(显示为空或NULL即可)
如果我们使用mybatis,第一个想到的解决办法可能是在Java程序里把用户信息查出来,然后再根据年龄做if判断。但是这样做有点繁琐。还好mybatis提供了一个标签(<discriminator/>)来解决如上的业务需求。discriminator也就是侦察器、也叫鉴别器
二、discriminator使用
还是结合第一节的业务问题来使用discriminator标签
映射文件配置
mapper.xml配置内容如下
<resultMap id="userMapForTestDiscriminator" type="user" autoMapping="false">
<!--关闭自动映射,那么没有指定的列名不会出现在结果集中-->
<id property="id" column="id"/>
<result property="username" column="username"/>
<result property="age" column="age"/>
<discriminator javaType="int" column="age">
<case value="18" resultType="user">
<result property="birthday" column="birthday"/>
</case>
</discriminator>
</resultMap>
<select id="selectDiscriminator" resultMap="userMapForTestDiscriminator">
select * from user limit 2
</select>
select标签的id为selectDiscriminator,并且返回结果集使用resultMap来接收。重点就在resultMap里配置了discriminator。先来解释一下discriminator的作用:
discriminator有个子标签是case,并且指定侦察器鉴别的属性为age。(它的用法很类似于Java中的switch)
当查询的结果集中age列数据等于case指定的value值时(在这个例子里就是当结果集中age列为18时)。则把case标签中的result标签加入到外部的resultMap标签中。反之——如果结果集中的age列值不为18,则不做任何操作。
换个更直观的说法来看。
- 当结果集中的age列等于18时(本例中)实际上返回的resultMap标签相当于
<resultMap id="userMapForTestDiscriminator" type="user" autoMapping="false">
<!--关闭自动映射,那么没有指定的列名不会出现在结果集中-->
<id property="id" column="id"/>
<result property="username" column="username"/>
<result property="age" column="age"/>
<result property="birthday" column="birthday"/>
</resultMap>
- 当结果集中的age列不等于18时(本例中)实际上返回的resultMap标签相当于
<resultMap id="userMapForTestDiscriminator" type="user" autoMapping="false">
<!--关闭自动映射,那么没有指定的列名不会出现在结果集中-->
<id property="id" column="id"/>
<result property="username" column="username"/>
<result property="age" column="age"/>
</resultMap>
怎么样?是不是和Java中的Switch用法一模一样,当满足条件时就执行case语句中的代码。
Mapper接口配置
public interface UserMapper {
List<User> selectDiscriminator();
}
测试
@Test
public void test1() throws Exception {
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
List<User> users = userMapper.selectDiscriminator();
for (Object user : users) {
System.out.println(user);
}
}
输出结果:User(id=1, username=0.620544543088072, age=18, password=222, birthday=2002-10-27, author=null)
User(id=3, username=0.620544543088072, age=22, password=null, birthday=null, author=null)

从输出结果中已经可以看到,当age不等于18的时候,birthdary字段没有值。那么mybatis是如何实现这个功能的呢?下面来从源码角度分析下。
总结
discriminator相当于Java中的Switch,作用是可以动态的控制resultMap标签中的result标签。
三、discriminator原理
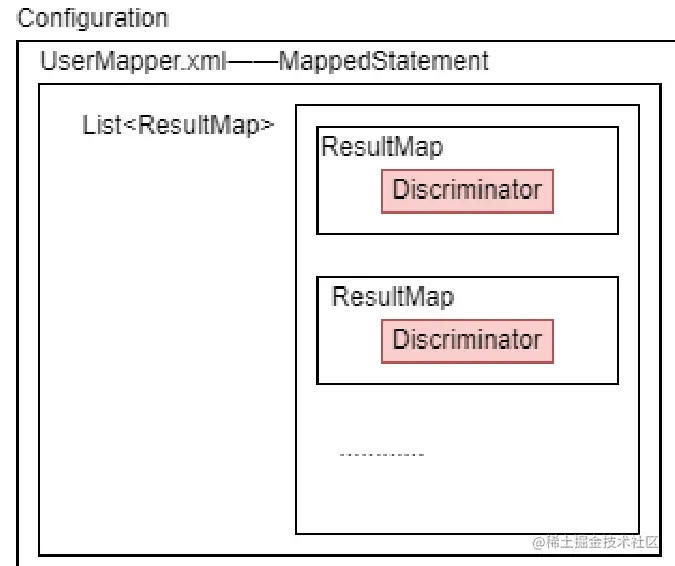
mybatis初始化的时候会加载映射配置文件。
- 把所有的
XxxMapper.xml文件解析为MappedStatement对象保存在Configuration对象中。以便于后续的调用。 - 而每个
XxxMapper.xml中的resultMap标签都会被解析为ResultMap对象存储在MappedStatement对象当中 - ResultMap标签中的每个
discriminator标签都会被解析为Discriminator对象存储在ResultMap对象当中。
至此,Discriminator所在的层级就是:
下面就从源码的两个方面揭开discriminator的面纱。
初始化时——加载配置文件并把discriminator标签解析为Discriminator对象存储到内存中。
执行SQL时——如果检测到有与该SQL匹配的Discriminator对象,则调用Discriminator对象的逻辑
Discriminator对象结构
public class Discriminator {
private ResultMapping resultMapping;
private Map<String, String> discriminatorMap;
}
Discriminator对象有两个字段
- resultMapping记录的是
<discriminator javaType="int" column="age">中的age字段的相关信息(列名、jdbc类型、Java类型、是否嵌套等等。总之记录的是鉴别器鉴别的那个列的列信息。而这个信息被封装成了ResultMapping对象,比较简单感兴趣的可以看下ResultMapping对象源码) - discriminatorMap记录的是
<case value="18" resultType="user">case标签的信息。它是一个map结构,key是case中value属性的值,value是resultmap的的唯一标识。(mybatis会通过resultMap的唯一标识去configuration对象中寻找对应的resultMap)
初始化
看到这里,默认读者有看过一定的mybatis源码。mybatis在启动时通过XMLMapperBuilder来加载映射文件(xml文件)。其中包含了对ResultMap标签的解析过程。具体逻辑在XMLMapperBuilder#resultMapElement方法中。代码如下(只列出了有关Discriminator的逻辑)
private ResultMap resultMapElement(XNode resultMapNode, List<ResultMapping> additionalResultMappings, Class<?> enclosingType) {
// 1. 解析配置文件的标签创建为Discriminator对象
Discriminator discriminator = processDiscriminatorElement(resultChild, typeClass, resultMappings);
// 2. 构建ResultMapResolver对象,再调用resolve方法创建ResultMap对象,Discriminator就是在resolve方法中被ResultMap对象中的
// 说白了是构建ResultMap的辅助类。
ResultMapResolver resultMapResolver = new ResultMapResolver(builderAssistant, id, typeClass, extend, discriminator, resultMappings, autoMapping);
return resultMapResolver.resolve();
}
调用processDiscriminatorElement方法为Discriminator对象设置详细的属性。
private Discriminator processDiscriminatorElement(XNode context, Class<?> resultType, List<ResultMapping> resultMappings) {
// 通过 column javaType jdbcType typeHandler javaTypeClass typeHandlerClass
// 来构造Discriminator对象中的resultMapping字段
String column = context.getStringAttribute("column");
String javaType = context.getStringAttribute("javaType");
String jdbcType = context.getStringAttribute("jdbcType");
String typeHandler = context.getStringAttribute("typeHandler");
Class<?> javaTypeClass = resolveClass(javaType);
Class<? extends TypeHandler<?>> typeHandlerClass = resolveClass(typeHandler);
JdbcType jdbcTypeEnum = resolveJdbcType(jdbcType);
Map<String, String> discriminatorMap = new HashMap<>();
// 遍历discriminator标签,把case节点的信息封装为Discriminator对象中的discriminatorMap字段
for (XNode caseChild : context.getChildren()) {
String value = caseChild.getStringAttribute("value");
String resultMap = caseChild.getStringAttribute("resultMap", processNestedResultMappings(caseChild, resultMappings, resultType));
discriminatorMap.put(value, resultMap);
}
// 调用辅助类整整的构建Discriminator对象
return builderAssistant.buildDiscriminator(resultType, column, javaTypeClass, jdbcTypeEnum, typeHandlerClass, discriminatorMap);
}
至此,Discriminator对象就被完整的创建出来了。它会被添加在ResultMap对象中缓存。后续程序执行过程中,就能通过Configuration对象获取MappedStatement对象,再通过MappedStatement对象获取ResultMap对象,再通过ResultMap对象就可以获取Discriminator对象啦!
需要注意的是,每个case标签都会被解析为一个结果集间接存入到configuration对象中。
执行SQL时
在程序通过mybatis执行数据库操作时,会通过ResultSetHandler对象来处理数据库返回的结果集。ResultSetHandler是mybatis的几个核心对象之一。它在DefaultResultSetHandler#resolveDiscriminatedResultMap方法中进行对Discriminator的逻辑处理。方法代码如下
public ResultMap resolveDiscriminatedResultMap(ResultSet rs, ResultMap resultMap, String columnPrefix) throws SQLException {
// 1 通过resultMap获取鉴别器对象Discriminator
Discriminator discriminator = resultMap.getDiscriminator();
while (discriminator != null) {
// 2. 从鉴别器中获取结果集中对应的需要被鉴别的值。拿文章开头的业务举例,在此就是获取结果集中的age列的值,第一行age的值是18。也就是value的值为18。第二行age的值为22
final Object value = getDiscriminatorValue(rs, discriminator, columnPrefix);
final String discriminatedMapId = discriminator.getMapIdFor(String.valueOf(value));
// 3. 判断configuration对象中是否有指定的resultMap对象,后面会根据这个resultMap进行映射结果集
if (configuration.hasResultMap(discriminatedMapId)) {
resultMap = configuration.getResultMap(discriminatedMapId);
}
}
return resultMap;
}
代码逻辑的大致步骤如下
- 通过resultMap获取鉴别器对象Discriminator
- 从鉴别器中获取结果集中对应的需要被鉴别的值。拿文章开头的业务举例,在此就是获取结果集中的age列的值,第一行age的值是18。也就是value的值为18。第二行age的值为22
- 获取case中的值,在本例中case会拿age的值和18做比较,如果比较不相等则不做处理,否则会把对应的resultMap的值返回,交给
ResultSetHandler去处理映射关系。
以上就是MyBatis discriminator标签原理实例解析的详细内容,更多关于MyBatis discriminator标签的资料请关注码农之家其它相关文章!








