为找教程的网友们整理了相关的编程文章,网友侯从阳根据主题投稿了本篇教程内容,涉及到Mybatis-Plus批量插入、Mybatis-Plus批量插入用法、Mybatis-Plus批量插入相关内容,已被869网友关注,相关难点技巧可以阅读下方的电子资料。
Mybatis-Plus批量插入
mybatis-plus的IService接口默认提供saveBatch批量插入,也是唯一一个默认批量插入,在数据量不是很大的情况下可以直接使用,但这种是一条一条执行的效率上会有一定的瓶颈,今天我们就来研究研究mybatis-plus中的批量插入。
1. 准备测试环境
新建一个测试表,用插入5000条数据来测试
CREATE TABLE `users` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `create_time` datetime DEFAULT CURRENT_TIMESTAMP, `user_name` varchar(255) DEFAULT NULL, `age` int(11) DEFAULT NULL, `email` varchar(255) DEFAULT NULL, `address` varchar(255) DEFAULT NULL, `account` varchar(255) DEFAULT NULL, `password` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=60204 DEFAULT CHARSET=utf8;
pom依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.10</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.2</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.13</version>
</dependency>
</dependencies>
yml配置
spring:
application:
name: example-server
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/my_user?useUnicode=true&characterEncoding=utf8&useSSL=false&allowMultiQueries=true&serverTimezone=Asia/Shanghai
username: root
password: root
main:
allow-circular-references: true
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl #开启SQL语句打印实体类
/**
* @description: 默认驼峰转换
* @author: yh
* @date: 2022/8/29
*/
@Data
public class Users extends Model<Users> {
/**
* id自增
*/
@TableId(value = "id", type = IdType.AUTO)
private Long id;
private LocalDateTime createTime;
private String userName;
private Integer age;
private String email;
private String address;
private String account;
private String password;
}UsersMapper
public interface UsersMapper extends BaseMapper<Users> {
}UsersMapper.xml
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="com.example.mapper.UsersMapper"> </mapper>
service接口
public interface UsersService extends IService<Users> {
}service实现
@Service
public class UsersServiceImpl extends ServiceImpl<UsersMapper, Users> implements UsersService {
}配置扫描
@MapperScan("com.example.mapper")
@SpringBootApplication
public class SpringExampleApplication {
public static void main(String[] args) {
SpringApplication.run(SpringExampleApplication.class, args);
}
}环境准备完成。
2. saveBatch
@RequestMapping(value = "/api")
@RestController
@Slf4j
public class ExampleController {
@Autowired
private UsersService usersService;
@RequestMapping(value = "/load", method = RequestMethod.GET)
public void load() {
List<Users> list = new ArrayList<>();
for (int i = 0; i < 5000; i++) {
Users users = new Users();
users.setUserName("yy" + i);
users.setAge(18);
users.setEmail("123@qq.com");
users.setAddress("临汾" + i);
users.setAccount("account" + i);
users.setPassword("password" + i);
list.add(users);
}
long start = System.currentTimeMillis();
usersService.saveBatch(list);
long end = System.currentTimeMillis();
System.out.println("5000条数据插入,耗时:" + (end - start));
}
}执行过程:
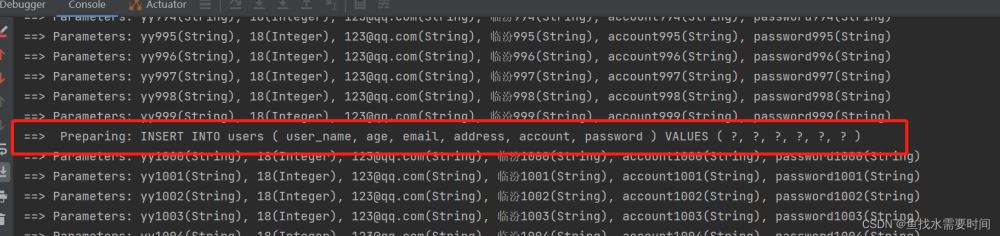


5000条数据被分成了5次执行,每次1000条,整体是一个事务
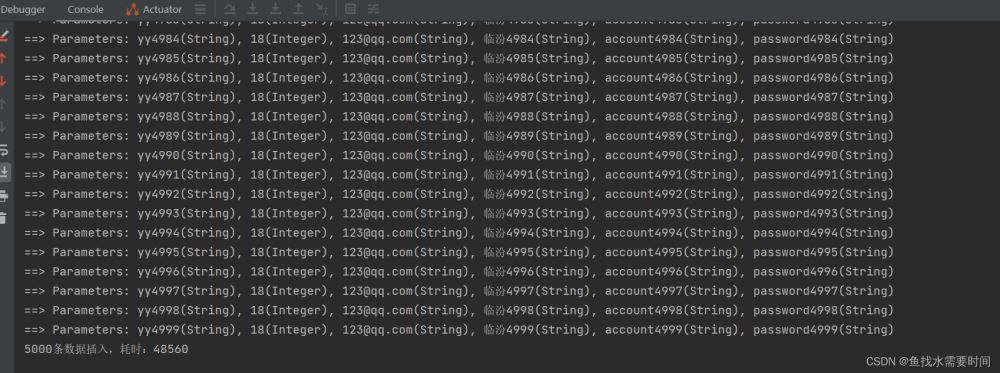
耗时:48.5秒
2.1 分析
点进saveBatch方法,看看内部是怎么实现的
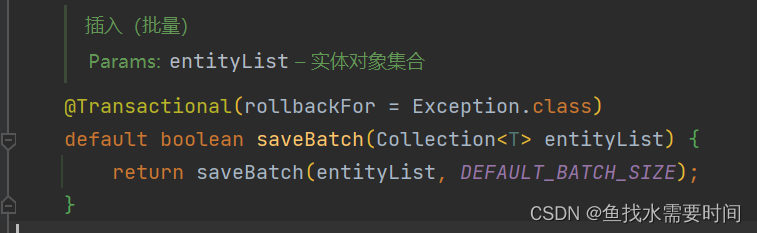
注意看,方法有一个事务注解,说明插入整批数据会作为一个事务进行

默认1000条一次,怪不得执行时每隔1000条会处于一个准备执行状态,等待几秒后才会往下执行(这里等待的时间就是1000个单条的insert语句执行的时间)
再往下点是一个saveBatch接口,参数分别是插入的对象集合、插入批次数量也就是默认的1000
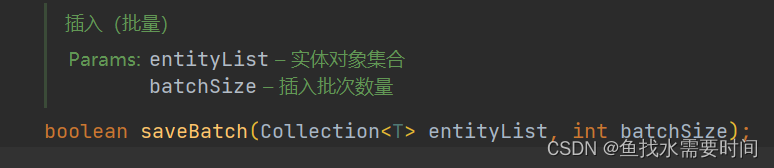
查看它的实现类
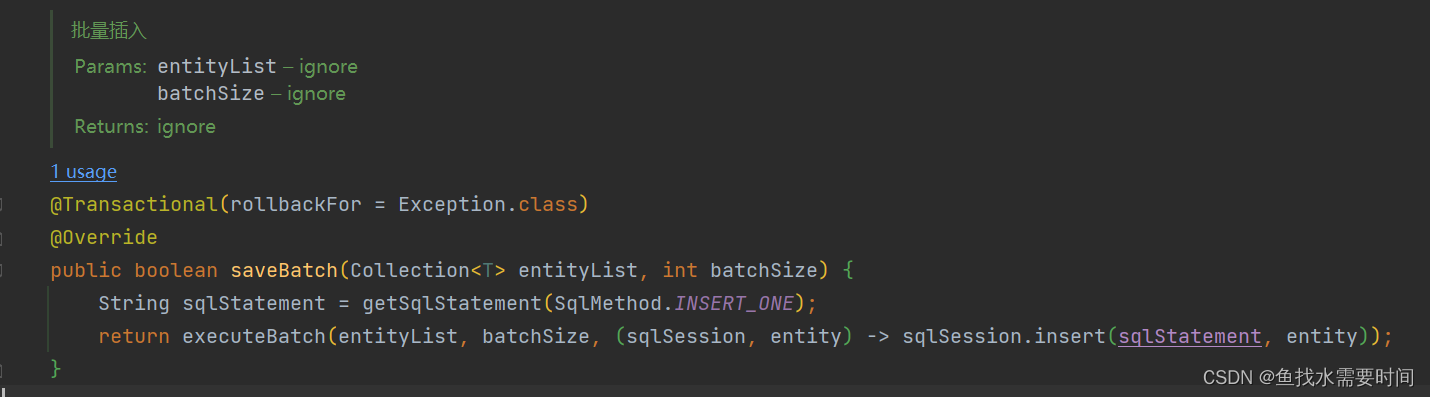
这里也有一个事务的注解,这是因为saveBatch是一个重载方法,插入的时候也可以指定插入批次数量调用

继续往下进入executeBatch
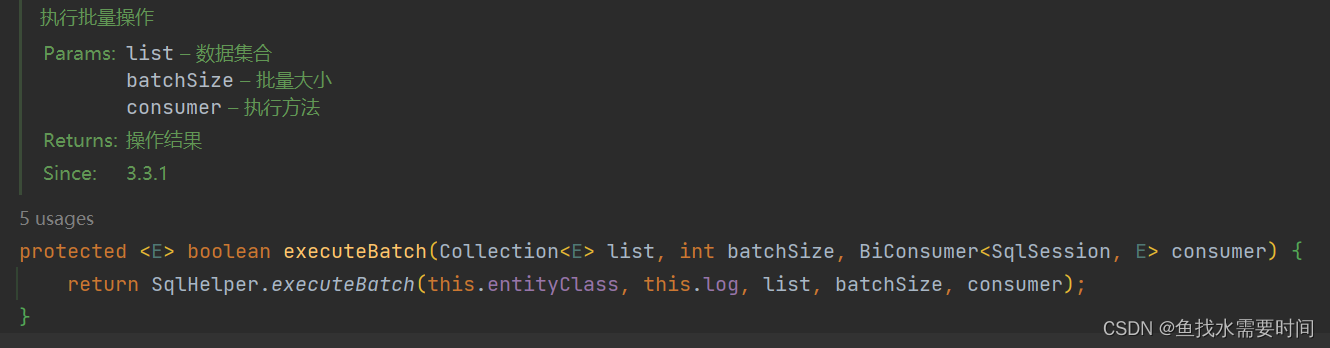
再往下
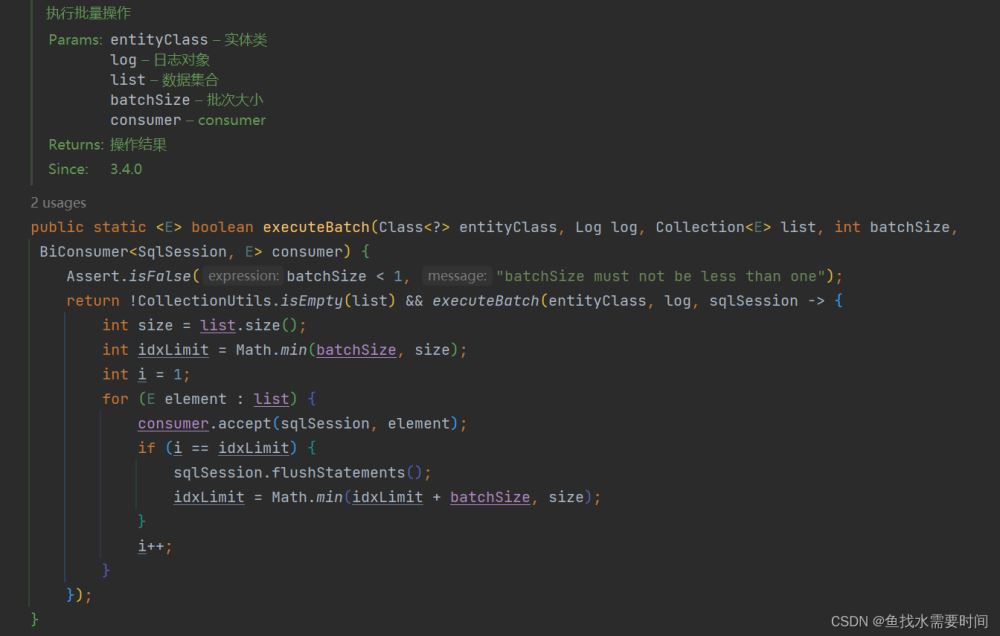
这里就是真正执行的方法了,idxLimit会对比DEFAULT_BATCH_SIZE和集合长度两个数中的最小数,作为批量大小,也就是说当集合长度不够1000,那么执行的时候批量大小就是集合的长度,就执行一次。
for循环中的consumer:对应的类型是一个函数式接口,代表一个接受两个输入参数且不返回任何内容的操作符。意思是给定两个参数sqlSession、循环中当前element对象,执行一次传递过来的consumer匿名函数。也就是上边源码里的插入匿名函数。
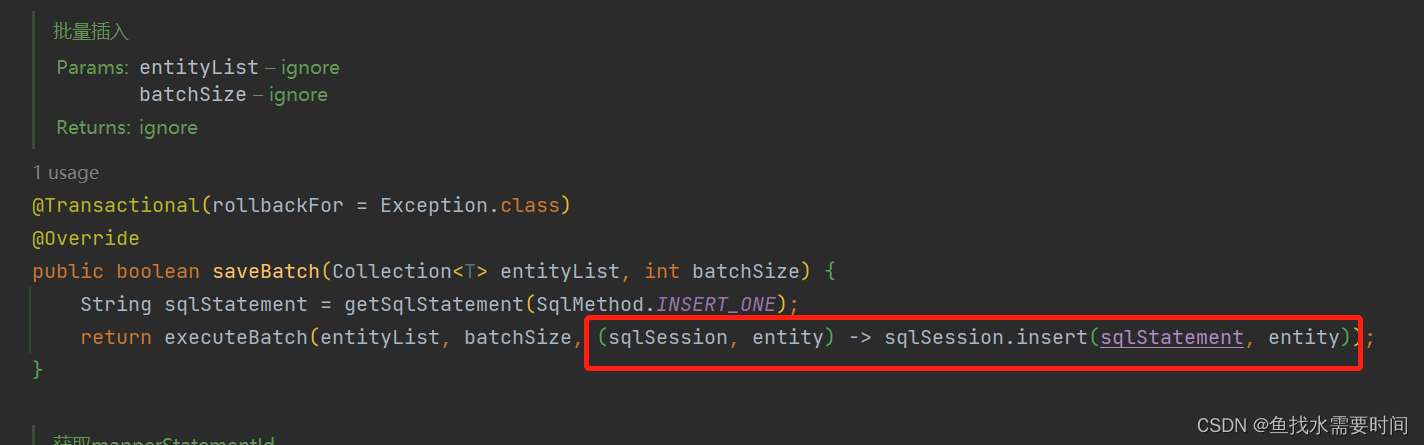
当i == indLimit时:执行一次预插入,并重新计算idxLimit的值
if中idxLimit计算规则:当前idxLimit加batchSize(默认1000) 和 集合长度 取最小值,计算出来的结果肯定不会超过集合的长度,最后的批次时idxLimit等于集合的长度,将这个值作为下一次执行预插入的时间点。
sqlSession.flushStatements():当有处于事务中的时候,起到一种预插入的作用,执行了这行代码之后,要插入的数据会锁定数据库的一行记录,并把数据库默认返回的主键赋值给插入的对象,这样就可以把该对象的主键赋值给其他需要的对象中去了,这里不是事务提交啊。
最后方法执行完后@Transactional注解会默认提交事务,如果调用的方法上还有@Transactional注解,默认的事务传播类型是Propagation.REQUIRED,不会新开启事务,如果没有@Transactional注解才会新开起事务
解析spring事务管理@Transactional为什么要添加rollbackFor=Exception.class
3. insert循环插入
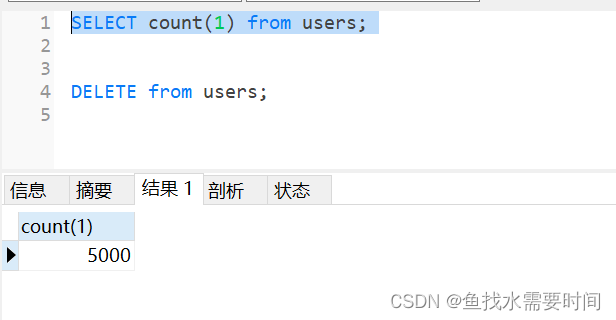
把数据库中的数据清空,还原到空表状态
@Service
public class UsersServiceImpl extends ServiceImpl<UsersMapper, Users> implements UsersService {
@Override
public void insertList() {
List<Users> list = new ArrayList<>();
for (int i = 0; i < 5000; i++) {
Users users = new Users();
users.setUserName("yy" + i);
users.setAge(18);
users.setEmail("123@qq.com");
users.setAddress("临汾" + i);
users.setAccount("1" + i);
users.setPassword("pw" + i);
list.add(users);
}
long start = System.currentTimeMillis();
for (int i = 0; i < list.size(); i++) {
baseMapper.insert(list.get(i));
}
long end = System.currentTimeMillis();
System.out.println("5000条数据插入,耗时:" + (end - start));
}
}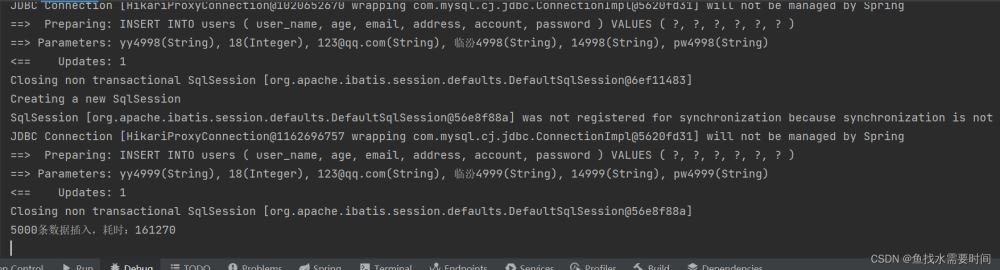
5000条数据每条都是一个单独的事务。就是一条条插入,成功失败都不会互相影响
耗时:161.2秒
4. 自定义sql插入
UsersMapper.xml
<insert id="insertList">
insert into users(user_name, age, email, address, account, password) values
<foreach collection="list" item="it" separator=",">
(#{it.userName}, #{it.age}, #{it.email}, #{it.address}, #{it.account}, #{it.password})
</foreach>
</insert>UsersMapper
void insertList(@Param("list") List<Users> list);@Service
public class UsersServiceImpl extends ServiceImpl<UsersMapper, Users> implements UsersService {
@Override
public void insertList() {
List<Users> list = new ArrayList<>();
for (int i = 0; i < 5000; i++) {
Users users = new Users();
users.setUserName("yy" + i);
users.setAge(18);
users.setEmail("123@qq.com");
users.setAddress("临汾" + i);
users.setAccount("1" + i);
users.setPassword("pw" + i);
list.add(users);
}
long start = System.currentTimeMillis();
baseMapper.insertList(list);
long end = System.currentTimeMillis();
System.out.println("5000条数据插入,耗时:" + (end - start));
}
}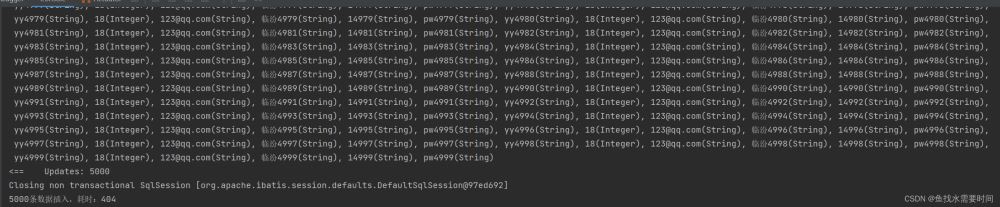
这里是把要插入的数据拼接在一个insert语句后面执行
INSERT INTO users (user_name,age,email,address,account,password) VALUES (?,?,?,?,?,?) , (?,?,?,?,?,?) , (?,?,?,?,?,?).....
这种效率是最高的,但是这种需要我们在每个批量插入对应的xml中取写sql语句,有点不太符合现在提倡的免sql开发,下面介绍一下它的升级版
5. insertBatchSomeColumn
mybatis-plus提供了InsertBatchSomeColumn批量insert方法。通过SQL 自动注入器接口 ISqlInjector注入通用方法 SQL 语句 然后继承 BaseMapper 添加自定义方法,全局配置 sqlInjector 注入 MP 会自动将类所有方法注入到 mybatis 容器中。我们需要通过这种方式注入下。
MySqlInjector.java
/**
* 自定义Sql注入
* @author: yh
* @date: 2022/8/30
*/
public class MySqlInjector extends DefaultSqlInjector {
@Override
public List<AbstractMethod> getMethodList(Class<?> mapperClass, TableInfo tableInfo) {
List<AbstractMethod> methodList = super.getMethodList(mapperClass, tableInfo);
//增加自定义方法,字段注解上不等于FieldFill.DEFAULT的字段才会插入
methodList.add(new InsertBatchSomeColumn(i -> i.getFieldFill() != FieldFill.DEFAULT));
return methodList;
}
}MybatisPlusConfig.java
@Configuration
public class MybatisPlusConfig {
@Bean
public MySqlInjector sqlInjector() {
return new MySqlInjector();
}
}自定义MyBaseMapper
public interface MyBaseMapper <T> extends BaseMapper<T> {
int insertBatchSomeColumn(List<T> entityList);
}mapper继承的这里也改下
public interface UsersMapper extends MyBaseMapper<Users> {
}插入的时候过滤字段,需要配置属性
@Data
public class Users extends Model<Users> {
/**
* id
*/
@TableId(value = "id", type = IdType.AUTO)
private Long id;
// 插入的时候过滤这个字段,默认值就是FieldFill.DEFAULT
@TableField(fill = FieldFill.DEFAULT)
private LocalDateTime createTime;
@TableField(fill = FieldFill.INSERT)
private String userName;
@TableField(fill = FieldFill.INSERT)
private Integer age;
@TableField(fill = FieldFill.INSERT)
private String email;
@TableField(fill = FieldFill.INSERT)
private String address;
@TableField(fill = FieldFill.INSERT)
private String account;
@TableField(fill = FieldFill.INSERT)
private String password;
}修改一下service调用
@Service
public class UsersServiceImpl extends ServiceImpl<UsersMapper, Users> implements UsersService {
@Autowired
private SqlSessionFactory sqlSessionFactory;
@Override
public void insertList() {
List<Users> list = new ArrayList<>();
for (int i = 0; i < 5000; i++) {
Users users = new Users();
users.setUserName("yy" + i);
users.setAge(18);
users.setEmail("123@qq.com");
users.setAddress("临汾" + i);
users.setAccount("1" + i);
users.setPassword("pw" + i);
list.add(users);
}
long start = System.currentTimeMillis();
baseMapper.insertBatchSomeColumn(list);
long end = System.currentTimeMillis();
System.out.println("5000条数据插入,耗时:" + (end - start));
}
}运行结果:
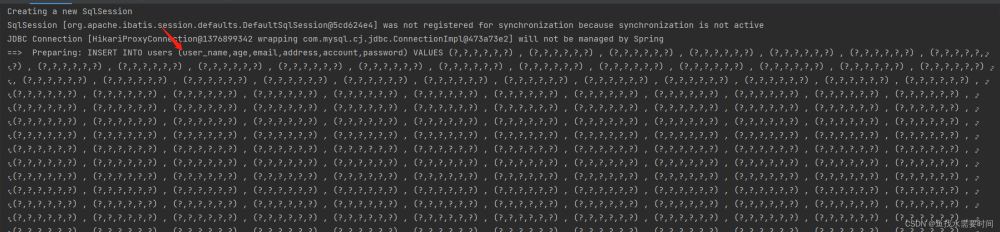
createTime字段被过滤掉了

执行时间和上边自定义sql一样,在1秒内浮动,如果量太大几十万条建议多线程分批处理。
参考文章
到此这篇关于Mybatis-Plus批量插入应该怎么用的文章就介绍到这了,更多相关Mybatis-Plus批量插入内容请搜索码农之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持码农之家!








